01
谈合作:把最好的估算引擎,
带来最有价值的数据
Frank:
现在在历史上发挥着重要的作用。对于我们来说,就能带给数据和小型企业的关系。我们还要启用这项技术,以及让整个服务堆栈来有效地使用它。我不想使用「天作之合」来比喻,然而对于一个门外汉,是一个挺好的机会,踏入到这扇机会的正门里。
黄仁勋:
我们是,而不是对手。我们要把世界上最好的估算引擎带到世界上最有价值的数据。回忆过去,我早已工作了很长时间,而且还没有这么老。Frank,你更老一些(笑)。
近期,因为众所周知的成因,数据是很大的,数据是宝贵的。它应当是安全的。联通数据很困难,数据的引力真实存在。因而,对我们来说,把我们的估算引擎带到上要容易得多。我们的伙伴关系是加快,但它只是关于将人工智能带到。
最核心的是,数据+人工智能算法+估算引擎的组合,我们的伙伴关系将所有这三件事结合在一起。令人无法置信的有价值的数据,令人无法置信的伟大的人工智能,令人无法置信的伟大的估算引擎。
我们可以一起做的事情,是帮助顾客使用它们的专有数据,并用它来撰写AI应用程序。你晓得,这儿的重大突破是,你第一次可以开发一个小型语言模型。你把它放到你的数据后面,于是你与你的数据谈话,如同你与一个人谈话一样,而这种数据将被提升到一个小型语言模型中。
小型语言模型加知识库的组合等于一个人工智能应用。这一点很简略,一个小型的语言模型将任何数据知识库弄成一个应用程序。
想想人们所写的一切惊人的应用程序。它的核心仍然是一些有价值的数据。今天你有一个查询引擎通用查询引擎在上面,它超级智能,你可以让它回应你,但你也可以把它连结到一个代理,这是和向量数据库带给的突破。将数据和大语言模型叠加的突破性的东西正在四处发生,每位人都想做。而Frank和我将帮助你们做到这一点。
02
硬件3.0:推行AI应用,
解决一个特定问题
主持人:
作为投资者来看这些变化,硬件1.0是十分确定的代码,由安装工程师根据功能写下来;硬件2.0是用仔细搜集的标记的训练数据优化一个血管网路。
大家在帮助人们拉动硬件3.0,这套基础模型原本有令人无法置信的能力,但他们依然须要与企业数据和自定义数据集合作。也是针对他们去开发这些应用程序要实惠得多。
对于这些深入关注这个领域的人来说有一个问题,基础模型是十分泛化,它可以做所有事情吗?为何我们还要自定义模型和企业数据呢?
Frank:
因此我们有特别泛化的模型,可以写诗,处理《了不起的盖茨比》的做摘要,做英语问题。
然而在商业中,我们不须要很多,我们还要的是一个,在一个特别窄小,而且十分复杂的数据集上斩获非凡的洞见。
我们还要了解商业方式和商业动态。那样的估算上不须要这么高昂,由于一个模型并不须要在一百万件事情上接受训练,只须要晓得十分少的、但很深入的主题。
举个实例。我是的监事会成员,我们一个大顾客,像和所有其他企业常面临的问题是,它们不断提高营销成本,来了一个顾客,顾客下了一个订单,顾客要么不回去,要么90天后回去,这十分不稳定。它们把这称为流失顾客。
这是复杂问题的剖析,由于顾客不回去的成因或许有好多。人们想找到这种问题的答案,它在数据中,不在通常的互联网中,并且可以通过人工智能找进去。这就是或许形成很大价值的反例。
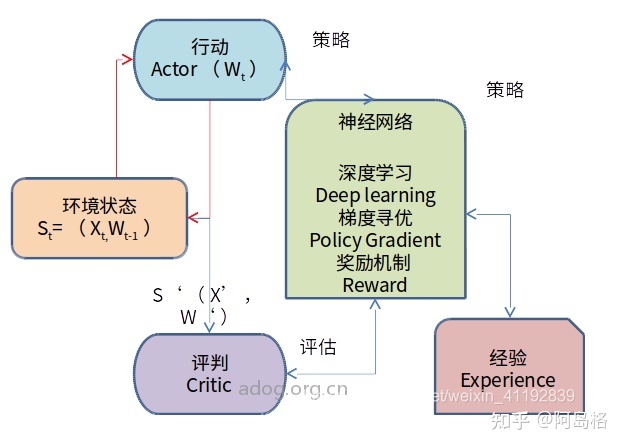
主持人:
这种模型应当怎样与企业数据互动?
黄仁勋:
我们的战略和产品是各类规格、最先进的预训练模型,有时你还要争创一个特别大的预训练模型,从而它可以形成,来教更小的模型。
而较小的模型几乎可以在任何设备运行,虽然推迟十分低。因此它的泛化能力并不高,zeroshot(零样本学习)能力或许更有限。
然而,你或许有几种不同类别不同大小的模型2023搜索引擎营销的定义,但在每一种状况下,你应当做监督的微调,你应当做RLHF(人类反馈的加强学习),从而它与你的目标和原则保持一致,你还要用矢量数据库之类的东西来提高它,因此所有那些都汇集在一个平台上。我们有技能、知识和基本平台,帮助她们争创自己的人工智能,于是将其与中的数据连结上去。
目前,每位企业顾客的目标不应当是探讨我怎么构建一个小型的语言模型,它们的目标应当是,我怎么构建一个人工智能应用程序来解决特定的问题?那种应用或许须要17个问题来做,最终得出正确的答案。之后你或许会说,我想写一个程序,它或许是一个SQL程序,或许是一个程序,那样我就可以在未来自动做这个。
你还是要引导这个人工智能,让他最终能给你正确的答案。但在那以后,你可以争创一个应用程序,可以作为一个代理(Agent)24/7不间断地运行,寻求相关状况,并提早向你汇报。因此我们的工作就是帮助顾客推行这种人工智能的应用,这种应用是有安全围栏的、具体的、定制的。
最终,我们在未来都将成为智能制造商,其实雇佣职员,但我们将争创一大堆代理,他们可以用LangChain类似的东西来争创,连结模型、知识库、其他API,在云中布署,并将其连结到所有的数据。
你可以规模化地操作某些AI,并不断地加强这种AI。因而,我们每位人都将制造AI、运行AI车间。我们将把基础设施置于的数据库,顾客可以在哪里使用它们的数据,训练和开发它们的模型,操作它们的AI,所以,将是你的数据储存库和中行。
有了自己的数据铁矿,所有人都将在上运行AI车间。这是目标。
03
「核弹」虽贵,
直接用模型相当于「打1折」
黄仁勋:
我们在构建了有五个AI车间,其中四个是世界前500名的超级计算机,另一个正在上线。我们使用这种超级计算机来做预训练模型。因而,当你在中使用我们的NemoAI基础服务时,你将得到一个最先进的预训练模型,早已有几千万美金的成本投入其中,更不用说研制投入了。因此它是预先训练好的。
之后有一大堆其他的模型紧扣着它,这种模型适于微调、RLHF。所有此类模型的训练费用都要高得多。
然而,如今你早已将预训练模型适应于你的功能,适应于你的围栏,优化你希望它具备的技能或功能类别,用你的数据提高。因而,这将是一个更具费用效益的方式。
更重要的是,在几天内,而不是几个月。你可以在开发与你的数据连结的人工智能应用程序。
你应当才能在未来迅速确立人工智能应用程序。
由于我们今天看见它正在实时发生。早已有一些应用能否让你和数据聊天,例如。
主持人:
是的,在硬件3.0时代,95%的轮训成本早已由他人承当了。
黄仁勋:
(笑)是的,95%的折扣,我没法想像一个更好的交易。
主持人:
这是真正的动力,作为投资人,我看见在剖析、自动化、法律等领域的特别年青的公司,它们的应用已然在六个月或更短的时间内实现了真正的商业价值。其中一部份成因是它们从这种预先训练好的模型开始,这对企业来说是一个很大的机会。
黄仁勋:
每家公司还会有数百个,并且1000个人工智能应用程序,也是与你公司的各类数据相通。因此,我们所有人都应当擅于建立这种东西。
04
其实是数据找业务,
目前是业务找数据
主持人:
我经常从大企业参与者看到的一个问题是,我们应当去投资人工智能,我们还要一个新的堆栈(Stack)吗?应当怎样考虑与我们现有的数据堆栈相通?
Frank:
我觉得它在不断发展。模型们正逐步显得更别致、安全、更好地被管理。因此,我们没有一个真正明晰的观点,这就是每位人就会使用的参考构架?有些人将有一些中央服务的设置。谷歌有Azure中的人工智能版本,他们的这些顾客正在与Azure进行互动。
但我们不清楚哪些模型将主导,我们觉得市场将在使用难易、成本这种事上进行自我排序。目前只是是开始,不是最终的状态。
安全部委也会参与过来,关于版权的问题会被革新。今天我们对技术很着迷,现实中的问题也会被同时处理。
黄仁勋:
我们目前正经历60年来第一次根本性的估算平台转型。假如你刚才读了IBM360的新闻稿,你会看到关于中央处理单元、IO子系统、DMA控制器、虚拟显存、多任务、可扩充估算往前和向前端兼容,而这种概念,实际都是1964年的东西2023搜索引擎营销的定义,而这种概念帮助我们在过去六七年来,不断进行CPU扩充。
那样的扩充早已进行了60年了,但这早已走到了尽头。今天你们都明白,我们没法再扩充CPU了,忽然之间,硬件变化了。硬件的撰写方法,硬件的操作模式,以及硬件能做的事情都与先前有巨大的不同。我们称之前的硬件为硬件2.0。目前是硬件3.0。
事实就是,估算早已从根本上改变了。我们听到两个基本的动力在同时发生,这只是为何今天事情正在发生猛烈反弹。
一方面,你不能再不断地订购CPU。假如你今年再卖一大堆CPU,你的估算吞吐量将不会提高。由于CPU扩充的终点早已到来了。你会多花一大堆钱,你不会得到更多的吞吐量。为此,答案是你应当去加快(英伟达加快估算平台)。图灵奖荣获者提到了加快,英伟达引领了加快,加快估算目前早已到来。
另一方面是,计算机的整个操作系统发生了深刻的改变。我们有一个叫AI的层,而其中的数据处理、训练、推理布署,整个目前早已整合到或正在整合到中,然而,从开始数据处理,经常到最后的大模型布署,整个背后的估算引擎都被加快了。我们将赋能,在这儿你将才能做得更多,但是你将还能用更少的资源做到更多。
假如你去任何一个云,你会看见GPU是其中最高昂的估算实体。并且,假如你把一个工作负载放到旁边,你会发觉我们做得十分快。就好似你得到了一个95%的折扣。我们是最高昂的估算实体,但我们是最具费用效益的TCO。
因此,假如你的工作是运行工作负载,或许是训练小型语言模型,或许是微调小型语言模型,假若你想这么做,一定要进行加快。
加快每一个工作负载,这就是整个栈的重构。处理器因而发生变化,操作系统因而不同,大的语言模型是不同的,你写AI应用程序的形式是不同的。
未来,我们都要写应用。我们都要把我们的和我们的上下文,和少数几个命令连结上去,连结到大语言模型和自己的数据库或则公司的数据库中,开发自己的应用程序。每位人都将成为一个应用程序的开发者。
主持人:
但不变的是,它依然是你的数据。你一直还要对它进行微调。
Frank:
其实我们都认为更快的总是更贵的。实际上忽然之间,更快的是更实惠的,这是一种反直觉的东西。因而,有时人们想提高供应,以为那样更实惠,结果却更贵。
另一个与之前矛盾的是,其实都是数据去找业务(datagoingtowork),而如今,业务去找数据(workgoingtodata)。过去的六七年,或则更多年,我们仍然在让数据去找业务,这引起了大规模的信息荒岛。而假如你想拥有一个AI车间,用之前的做法将是十分困难的。我们应当把估算带到数据所在的地方。我觉得我们目前正在做的就是正确的方法。
05
企业怎么荣获
最快和最大的价值
Frank:
最快和荣获最大价值或许是两个很不一样的问题。
最快的话,你很快就能看见,数据库各处都上线了人工智能提升的搜索方法,由于这是最容易提高的功能。目前,并且一个文盲都能从数据中获取有价值的信息,这真十分不可思议,这是终极的交互民主化。搜索功能极大提高,你就向主界面提一个问题,他们可以把这种问题带到数据自己进行查询。这是挂在低处的果实,最容易的,我们觉得这是阶段一。
接下去,我们就开始真正关注真正的瓶颈,就是专有的企业数据,混和结构化的、非结构化的,所有那些,我们怎么调动这种数据?
我旁边早已提及了toC企业面临的流失率问题,供应链管理方面的问题。当供应链非常复杂的时侯,假如有一个丑闻发生了,我们怎么再次调整一个供应链,使其运转?我今天该如何做?供应链是由这些不同的实体组成的,不是单一的企业。历史上,这是一个未曾被估算解决过的问题。供应链管理从来没有产生过一个平台,它几乎是一个电子电邮,电子表格产生的机制,不仅一些小的例外。因而,这是十分令人激动的。
或则我们可以再次估算小型的呼叫中心的投资,优化零售的定价,像我说的,这是一个大企业的CEO们经常期盼的再次定义商业机制,是真正的潜力。
06
对企业的建议:
黄仁勋:
我会问自己,第一,哪些是我惟一最有价值的数据库?第二件事,我会问自己,假如我有一个超级、超级、超级聪慧的人,而企业的一切数据都经过那种超级智能,我会问哪个人哪些?
按照每位人的公司,这是不同的。Frank的公司顾客数据库极其重要,由于他有太多顾客。而我自己的公司,没有这么多顾客,但对我的公司而言,我的供应链超级复杂,但是我的设计数据库也超级复杂。
对来说,没有人工智能我们早已未能建造出GPU。由于我们的安装工程师都不或许像AI这样,为我们进行大量的迭代和探求。因而,当我们提出人工智能的时侯,第一个应用在我们自己的公司。并且,因此(英伟达超算产品)不或许没有人工智能的设计。
我们也会将我们自己的AI应适于我们自己的数据中。我们的错误数据库就是一个完美的应用场景。假如你看一下AI的代码量,我们有几百个硬件包,结合在一起,支持一个应用程序才能跑上去。我们今天正在努力的一些事情,就是怎样使用AI去弄清楚怎样给它打安全补丁,怎么最好地维护它,那样我们就可以毋须干扰整个下层应用层的同时,还能向前端兼容。
这都是AI才能为你提供答案的。我们可以用一个大语言模型去回答此类问题,为我们找到答案,或则向我们揭露一些问题,于是安装工程师就可以再将其修好。或则AI可以推荐一个修补方式,人类安装工程师再去确认这是不是一个好的修补方式。
我认为不是所有人都认识到了她们每天都在处理的数据旁边,然而蕴涵着多少智能、洞见和影响力没有被开掘。这就是为何我们所有人都要参与过来,帮助带给那样的未来。
目前,你储存在数据库房的数据,第一次可以被连结进人工智能车间。你将才能生产信息情报,这是世界上最有价值的商品。你坐在一个自然资源的铜矿上——你公司的专有数据,而我们今天把它连结到一个人工智能引擎上,另一端每次直接形成信息情报,以无法置信的情报量从另一端涌出,并且在你吃饭时也在源源不断地产出。这是有史以来最好的事情。
 名师辅导
环球网校
建工网校
会计网校
新东方
医学教育
中小学学历
名师辅导
环球网校
建工网校
会计网校
新东方
医学教育
中小学学历





 免费试听
免费试听

 今日
今日








 您现在的位置:
您现在的位置:









